OPICO 3: Algorithms for Item/Category Optimization
Part 3 in a series on: Optimization Problems with Items and Categories in Oracle
The knapsack problem is a problem in combinatorial optimization: Given a set of items, each with a weight and a value, determine the number of each item to include in a collection so that the total weight is less than or equal to a given limit and the total value is as large as possible.
The knapsack problem and many other problems in combinatorial optimization require the selection of a subset of items to maximize an objective function subject to constraints. A common approach to solving these problems algorithmically involves recursively generating sequences of items of increasing length in a search for the best subset that meets the constraints.
I applied this kind of approach using SQL for a number of problems, starting in January 2013 with A Simple SQL Solution for the Knapsack Problem (SKP-1), and I wrote a summary article, Knapsacks and Networks in SQL, in December 2017 when I put the code onto GitHub, sql_demos - Brendan’s repo for interesting SQL.
This is the third in a series of eight articles that aim to provide a more formal treatment of algorithms for item sequence generation and optimization, together with practical implementations, examples and verification techniques in SQL and PL/SQL.
List of Articles
- OPICO 1: Algorithms for Item Sequence Generation
- OPICO 2: SQL for Item Sequence Generation
- OPICO 3: Algorithms for Item/Category Optimization
- OPICO 4: Recursive SQL for Item/Category Optimization
- OPICO 5: Tuning Recursive SQL for Item/Category Optimization
- OPICO 6: Mixed SQL and PL/SQL Methods for Item/Category Optimization
- OPICO 7: Verification
- OPICO 8: Automation
GitHub 
- Optimization Problems with Items and Categories in Oracle
[See README for references]
Twitter 
In the second article, we explained how to use SQL and PL/SQL to implement the sequence generation algorithms described generically in the first.
In the current article, we extend consideration beyond just the generation of sequences to optimization problems where we want to select sequences that maximize a value measure subject to constraints. Both overall sequence measure aggregates and item category constraints are considered, and we show how the algorithms can be extended to eliminate infeasible, or suboptimal, paths as early as possible. We explain a technique for approximative solution, and show how it can be used within a two-level approach to obtain an exact solution more efficiently.
The discussion follows the first article in using mathematical symbolism where appropriate, and the mathematical approach again allows us to verify correctness of the algorithms, as well as facilitating the use of logic to maximize efficiency. In the next article we will demonstrate how a basic one-level algorithm can be implemented using recursive SQL.

Contents
↓ 1 Example: 3 Item Set Combinations from 6
↓ 2 Sequence Constraints
↓ 3 Sequence Value Optimization
↓ 4 Conclusion
1 Example: 3 Item Set Combinations from 6
The diagram shows the recursion process for generating sequences of 3 items from 6 of type Set Combination as a tree diagram, starting from the empty set as root.
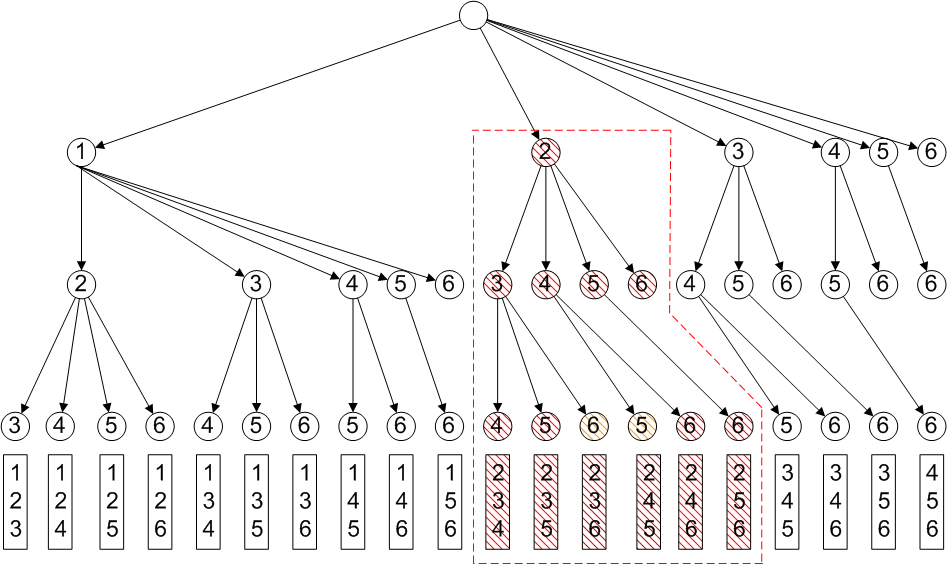
If we are generating sequences to solve combinatorial optimization problems with constraints, we may be able to eliminate nodes and their descendants. For example, if we have item prices and a limit on total price, we might be able to deduce that sequences starting with item 2 cannot meet the price limit and thus eliminate the shaded nodes early, reducing the computational work to be done.
2 Sequence Constraints
↑ Contents
↓ 2.1 Sequence Length
↓ 2.2 Measure Constraints
↓ 2.3 Item Category Constraints
In combinatorial optimization problems there are generally constraints on the solution sequences. For example, items may have associated measures, such as price or weight, and the sum of the measure values may be required to be between given limits; items can also be assigned to categories, with constraints on the numbers of items in each category allowed in solution sequences; and so on.
Once we have generated candidate sequences they may be tested against any constraints specified, infeasible sequences excluded, and the remaining sequences ranked in order of some measure of value.
However, there may be very large numbers of candidate sequences that would take a lot of resources to generate and test: We saw in the first article that there are 17,310,309,456,440 ways to choose 10 from 100 items in sequences of type SC, so it would be desirable to apply constraints during the generation process where possible.
In this section we’ll look at some ways of doing this, and we’ll restrict the discussion to the case of set combinations where now r, as well as n, are fixed and we’ll use k as the iteration index.
2.1 Sequence Length
One obvious constraint is that we do not need to generate subsequences that we can deduce cannot lead to full sequences of length r. For example, looking at the diagram above, items 5 and 6 need not be included in the level 1 1-item sequences, since, from our ordering mechanism they cannot lead to sequences of length 3.
In general, at level k-1 we need to generate the level k subsequences using the n - r + 1 items from k to n - (r - k) only.
2.2 Measure Constraints
↑ 2 Sequence Constraints
↓ Overall Measure Constraints
↓ Projected Measure Constraints
Overall Measure Constraints
Suppose we have a constraint on the sequences sought that the sum of the values of some item measure across the whole sequence must not exceed some limit.
If the measure is non-negative then once a subsequence has exceeded the limit, then all subsequences generated from it will also exceed the limit. We can therefore exclude that subsequence from further recursion.
We may be able to go further than that and exclude subsequences that have not yet exceeded the limit, but where we can deduce that any full sequence generated from it must do so.
Let 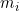 denote the value of a non-negative measure on item i, and
denote the value of a non-negative measure on item i, and 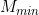 ,
, 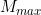 denote lower and upper limits on the sum of the measure across a sequence of the desired length, r,
denote lower and upper limits on the sum of the measure across a sequence of the desired length, r,  . Thus we have:
. Thus we have:
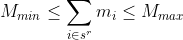
Projected Measure Constraints
Suppose we evaluate in advance the minimum and maximum values of m across all items, 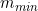 ,
, 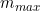 , so that:
, so that:
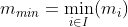
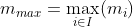
Then we can see that, given that the measure is non-negative, the following inequalities must hold for subsequences 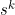 for k = 1,…,r - 1, if the constraints above are to hold for :
for k = 1,…,r - 1, if the constraints above are to hold for :
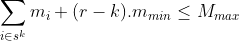
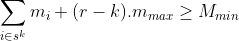
We can use these inequalities during the recursion process to exclude any items that cause them to be violated at an intermediate iteration, k. This can greatly reduce the amount of computation required to derive the feasible sequences of length r, .
In fact we can do better than this by evaluating in advance arrays of minimum and maximum sums of the measure for k items,  ,
, 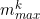 , for k = 1,…,r-1:
, for k = 1,…,r-1:
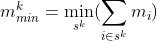
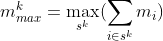
These arrays can be obtained simply by sorting the items by the measure values and taking the first and last r-1 items, respectively. The arrays can then be used in the (generally) more restrictive inequalities, for k = 1,…,r - 1:
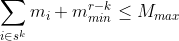
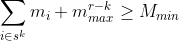
2.3 Item Category Constraints
↑ 2 Sequence Constraints
↓ Example
↓ Maximum Constraints
↓ Minimum Constraints
↓ Transition Constraints for Category Minima
In some problems we may have item category constraints, where each item is of a single category and the full sequences (, of length r) are required to have numbers of items in categories within given limits by category. Let’s say we have a set, C, of categories, and for each index j in C:
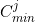 ,
, 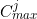 are lower and upper bounds on the numbers of items allowed in category j
are lower and upper bounds on the numbers of items allowed in category j
Let 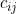 denote the incidence matrix of items against categories, so that = 1/0 as item i is/is not in category j
denote the incidence matrix of items against categories, so that = 1/0 as item i is/is not in category j
and, as each item is in exactly one category, for each i:
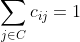
Then we can write the category constraints, for each j in C:
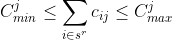
Example
↑ 2.3 Item Category Constraints
As with the measure constraints considered above, we could generate sequences of the correct length and then test them against the category constraints, but if we could apply constraints as early in the recursion process as possible, that would be more efficient. Consider the diagram below, where we have added colour-coded categories to the items in the tree diagram from earlier, with constraints as shown:
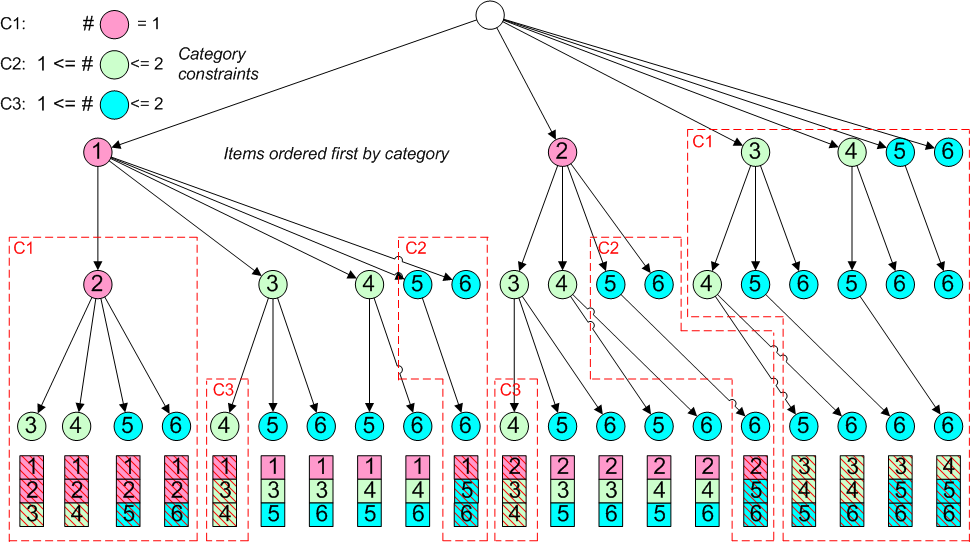
The combination types of sequence assume that items are ordered to avoid duplication within the recursion process. For problems with item category constraints it makes sense to use the category as the first attribute in the ordering. In the diagram the items are now ordered first by the category, so that items of the same category are consecutive in numbering. The red-dashed outlines show how nodes can be eliminated from consideration early in the process. For example, in the first box constraint C1 means that item 2 cannot follow item 1, so we can eliminate it and all descendants without further tests. Similarly, we need not consider any sequences that have items numbered above 2 in first position, as they violate constraint C1.
We need to consider the minimum and maximum category constraints separately.
Maximum Constraints
↑ 2.3 Item Category Constraints
In order for the maximum constraint to hold at the sequences of length r, it’s clear that it must hold, for each j in C, at all subsequences of lengths from k = 1,…,r:
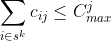
Minimum Constraints
↑ 2.3 Item Category Constraints
For the minimum constraint the inequality for r can’t just be replaced by one for k = 1,…,r as the thresholds can be met by later items in the full sequence.
Suppose that the categories themselves are ordered, with those having no minimum constraint (or, equivalently, zero minimum) at the end. Then define the running sum, 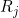 , of the minimum values from a given category j to the last one, m say. This is the minimum number of items required to meet all the minimum constraints from category j on.
, of the minimum values from a given category j to the last one, m say. This is the minimum number of items required to meet all the minimum constraints from category j on.
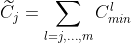
Now, for a given subsequence of items of length k, , let us also define the item and category identifiers at position k, 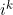 and
and 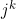 respectively:
respectively:
= identifier of item at position k in
= category identifier of item at position k in
Let us further define the running count of items in category j at position k, 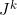 :
:
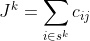
We then have an inequality that must hold for k = 1,…,r:
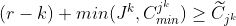
This inequality expresses the fact that, at position k, the number of remaining positions, (r - k), plus the count so far of items in the current category must be at least as great as the sum of the minimum category values for current and future categories. It assumes that items in the subsequences have ranks that increase with k, and that item ranks are consistent with category ranks (i.e. if the category rank of one item is higher than that of another item, then so is the item rank). The min clause ensures that if the constraint on the category for the k’th item has been met then excess items above the limit do not count against later categories (effectively the category is excluded from the inequality).
Applying this condition at each iteration will reduce the number of subsequences considered. We would like to ensure that any subsequences arrived at at the final iteration, of length r, will satisfy all the item category constraints. For the maximum constraints it’s easy to see that this will be true simply by applying the constraints at each iteration.
However, for the minimum constraints, applying the above inequality at each iteration will not be sufficient to guarantee this. If we consider the inequality at the final iteration:
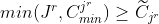
the right hand side has the sum the of the minimum limits for the category of the r’th item, and any categories ranked higher. This means that, for the inequality to hold, the limits on these latter categories, if any, must all be zero, and also the constraint on the category of the r’th item must be satisfied:
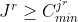
Transition Constraints for Category Minima
↑ 2.3 Item Category Constraints
To ensure all the category minimum constraints are satisfied, we therefore need to ensure that no prior category with non-zero minimum is omitted from the subsequence, and also that once such a category is encountered the following items must be in the same category until the minimum is achieved.
Given that items are now ordered first by category, this can be guaranteed by imposing restrictions on the transitions between categories:
- Once an item category appears in a subsequence, the following items must be in the same category until the category minimum is reached
- When an item category minimum is reached, the next item must be in the same category or in the next higher-ranked category or the next higher-ranked category has zero minimum
Representing these conditions symbolically:
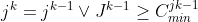
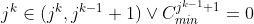
3 Sequence Value Optimization
↑ Contents
↓ 3.1 Bounding and Ranking
↓ 3.2 Subsequence Conditions
↓ 3.3 Iterative Refinement Algorithms
As noted at the beginning of this article, item sequences are often sought as solutions to combinatorial optimization problems. We showed in earlier sections how recursion can be used to generate sequences, and how constraints can be applied during the recursion process to eliminate subsequences that can’t lead to valid solutions as early as possible. In optimization problems the aim is to find, among the valid solutions, the best ones in terms of maximizing some value attribute.
3.1 Bounding and Ranking
↑ 3 Sequence Value Optimization
↓ Value Function and Ranking
↓ Projected Value Maxima
↓ Minimum Value Constraint
↓ Category-Partitioned Rank
Value Function and Ranking
If each item i has value 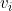 , we can define for a given sequence
, we can define for a given sequence 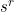 , the value function:
, the value function:
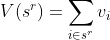
If we write 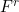 as the set of sequences that satisfy all constraints on measures and item categories, then the optimization problem could be defined as finding:
as the set of sequences that satisfy all constraints on measures and item categories, then the optimization problem could be defined as finding:
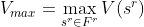
or:
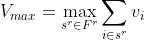
along with the that achieve the maximum.
More generally we may be interested in ranking the solutions and reporting the best N, say. Suppose we rank the solutions in descending order of value (V) and define a rank function as the index, (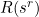 , say) in the list of solutions so ordered (for solutions of equal value assume some tie breaker is used to guarantee a unique ordering). Let us then define the rank as follows:
, say) in the list of solutions so ordered (for solutions of equal value assume some tie breaker is used to guarantee a unique ordering). Let us then define the rank as follows:
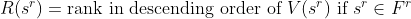
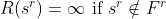
We can then express the optimization problem as that of finding the set of N best feasible solutions, 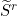 , where:
, where:
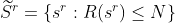
The most obvious way to obtain these solutions is to generate the set of valid (or ‘feasible’) solutions and then apply a standard sorting algorithm to that set. We have shown how measure and category constraints on the final sequences can be used to generate intermediate constraints that allow subsequences to be discarded early. It would be nice if we could find similar techniques to discard subsequences that we deduce could not lead to sequences in the ‘best’ solution set, and we’ll discuss this in the next section.
Projected Value Maxima
It will be useful to evaluate in advance an array of maximum sums of the value for k items, , for k = 1,…,r-1, in the same way as we did for the measures in equation 2.2.7:
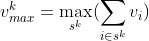
Minimum Value Constraint
It will also be useful to consider a constraint on the minimum allowed total value, of the form:
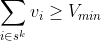
Category-Partitioned Rank
Finally, an additional rank will prove useful, similar to [3.1.4] and [3.1.5] above but for each k = 1,..,r and with the rank calculated separately for the partitions defined by the category multiset corresponding to the particular subsequence. We define the category-partitioned rank, (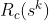 , say) as follows:
, say) as follows:

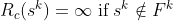
Note that 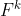 generalises to shorter subsequences, and is to be understood as the set of
generalises to shorter subsequences, and is to be understood as the set of 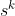 that are consistent with being subsequences of a member of .
that are consistent with being subsequences of a member of .
3.2 Subsequence Conditions
↑ 3 Sequence Value Optimization
↓ Constraint Conditions
↓ Value Filtering Conditions
In the first article, (section: SC: Set Combination [Items may not repeat, order does not matter]), we saw that the recursive generation of sequences of length k from those of length k-1 is effected by adding on to each of the subsequences each item ranked higher than the last item in the subsequence. We can rewrite the expression thus:
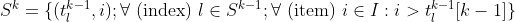
with the recursion starting from the empty set:
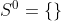
Constraint Conditions
When we add in the constraint conditions, we get an expression for the process of generating the set of feasible k-length subsequences from the k-1 set. In the first line [3.2.1] we define the iterations over the set of k-1-tuples with index l, and over the items i. The following lines then define the conditions that the new item i must satisfy for a given k-1-tuple of index l. Condition [3.2.2] ensures combinations only are selected (without permutations within them), conditions [3.2.3-3.2.8] correspond to the various measure and item category constraints discussed above.
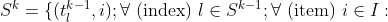
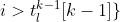
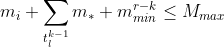
 max for measure
max for measure
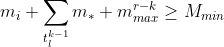
 min for measure
min for measure
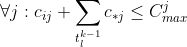 max for category j
max for category j
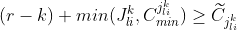
|
sum of count mins for remaining categories]
Note: 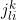 is category of item i in prospective l’th k-tuple
is category of item i in prospective l’th k-tuple
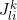 is running count of category of item i in prospective l’th k-tuple
is running count of category of item i in prospective l’th k-tuple
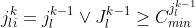
Note: 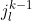 is category of last item in l’th (k-1)-tuple
is category of last item in l’th (k-1)-tuple
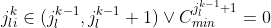
| or: next ranked category has zero count min
Note: Assumes category j is identified by its rank (1, 2, 3 etc.)
Value Filtering Conditions
We now introduce value filtering conditions aimed at further reducing the computational cost of searching.
Conditions [3.2.9-3.2.10] allow for exclusion of intermediate subsequences whose value ranks below a given number, partitioned by category multiset, or where the projected final value would be below some minimum value.
The condition [3.2.9] permits us to seek solutions without fully exploring the solutions space, and that thus are not guaranteed to be optimal, but that may be obtained with less computation.
The condition [3.2.10] permits us to seek only solutions that exceed a given minimum value.
While both these conditions can be rendered null by choosing sufficiently large maximum rank, and zero for the minimum value, we can use them together in a two-step algorithm to try to get a lower bound on the maximum value quickly, and then feed that back in to another iteration to obtain the exact solutions more quickly.
Value Rank Filtering
Now add a constraint on the (k-1)-tuple ranks:
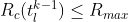
Value Bound Filtering
Now add a constraint on the minimum projected value:
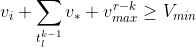
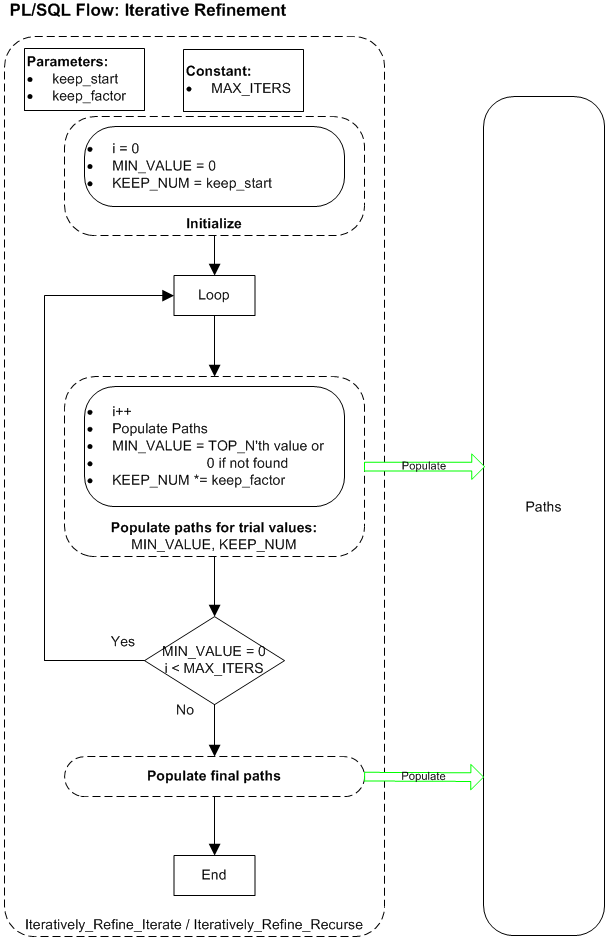
3.3 Iterative Refinement Algorithms
↑ 3 Sequence Value Optimization
In section 3.1.1 we made a recursive definition of the solution set at iteration k, 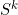 , in terms of the solution set at iteration k-1,
, in terms of the solution set at iteration k-1, 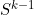 , for k = 1,…,r where the 0’th solution set is empty. This is based on
the conditions 3.2.1-3.2.10, where conditions 3.2.9 and 3.2.10 contain two parameters,
, for k = 1,…,r where the 0’th solution set is empty. This is based on
the conditions 3.2.1-3.2.10, where conditions 3.2.9 and 3.2.10 contain two parameters, 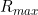 and
and 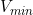 that are not part of the problem definition.
that are not part of the problem definition.
In [3.1.6] above we defined as the set of the best N feasible solution sequences of length r. In principle we can obtain this optimal set by applying the recursive set generation described above with conditions 3.2.1-3.2.8 only. However, this may involve a large amount of computation, and so we propose to make use of the two additional parameters and conditions within a two-level solution process.
Let us first express the as functions of the two parameters, for k = 1,…,r:
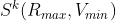
Now define, for l = 1,…,N, 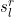 as the l’th best solution found, i.e.
as the l’th best solution found, i.e.  and
and 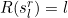 . Then we can define
. Then we can define 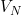 as the N’th best value:
as the N’th best value:
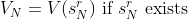
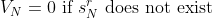
Suppose we have a sequence of increasing positive integers for , say 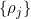 , that we will use as an input to the following two-level algorithm:
, that we will use as an input to the following two-level algorithm:
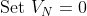
For
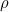 in Loop
in Loop
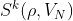
End Loop
Explanation
At each outer iteration we generate the next solution set based on two parameters. The first parameter, (for ) for smaller values should speed up the computation but at the expense of causing the generated set to be possibly sub-optimal. We can then take the N’th best solution value, , as a lower bound on the actual N’th best solution value, which may then speed up the generation process at the next iteration, and this time without compromising optimality. As we increase the value of it will at some point become non binding and therefore the exact optimal solution set will be generated.
The selection of the would be based on trial and error initially to determine how to find the exact optimal solution set most quickly, or alternatively, to find a good, possibly sub-optimal solution set quickly. A geometric progression might be a reasonable strategy, e.g. {10, 100, 1000,…}. We might also decide to use an [Exit When condition] such as to exit the loop once a solution has been found using a non-zero value for , or some variation on this idea.
We will demonstrate this in a PL/SQL implementation in the sixth article in this series, from which the following diagram is extracted:
4 Conclusion
In the first article in this series we showed how recursive techniques may be used to generate sequences of items that can form the basis of solutions for larger problems. In this article we extended that approach, first to handle constraints on item measures and on item categories, and then to the problem of optimizing a value function subject to the constraints. This allowed us to determine a set of simple conditions on the items considered at a given iteration, and on the allowable transitions from the previous to the next item.
These conditions allow for early truncation of subsequences based on projections for bounds on the possible values for full length sequences.
We extended this approach to include Value Filtering conditions, based on having lower bounds on the possible objective function value, and on approximative techniques: In combination these allow for two-level algorithms that can obtain exact solutions much more efficiently than one-level algorithms.
As in the first article, the mathematical treatment allows us to verify correctness of the algorithms, as well as facilitating the use of logic to maximize efficiency.
In the next article we will demonstrate how the basic one-level algorithm can be implemented using recursive SQL.
In the fifth article we will introduce test problems of realistic size, and tune performance using techniques including hints and the use of temporary tables to pre-calculate values.
In the sixth article we will demonstrate how PL/SQL can be used to implement both recursive and iterative versions of the basic algorithm with embedded SQL, and we’ll go on to implement a two-level Iterative Refinement algorithm that will prove to be highly efficient.